
Controladores PACs y soluciones de alta disponibilidad
Los controladores PAC tienen un gran número de prestaciones, que van más lejos del propio control de una instalación, y una de ellas es permitir soluciones de alta disponibilidad mediante técnicas de redundancia del hardware. Estas técnicas son sutilmente diferentes en función del PAC usado, por lo que solo vamos a describir algunas de las más comúnmente empleadas, para conseguir mejorar la disponibilidad de una instalación controlada por PACs.
La disponibilidad de un sistema es el porcentaje de tiempo que está funcionando y preparado para ejecutar su misión. Se suele referir a este valor por su cantidad de “nueves” para simplificar la anotación.
¿Pero que es la “alta disponibilidad”? La alta disponibilidad es un concepto en el que se compara la disponibilidad de un sistema simple con el mismo sistema teniendo redundados total o parcialmente sus componentes.
Invertir en un sistema redundante de alta disponibilidad, en contraposición a uno de disponibilidad simple, puede tener una gran diferencia en pérdida de tiempo o costes debidos a paradas no planificadas.
Para aumentar la disponibilidad de un sistema controlado por un PAC se suelen implementar todas o algunas de las técnicas que pasamos a describir.
Redundancia de controladores
El punto que se suele considerar más crítico y por tanto suele ser el primero en redundarse son los propios controladores PAC. Pasar de un sistema con una sola tarjeta controladora o CPU a dos mediante la duplicidad de los propios chasis donde reside dicha CPU es la primera opción. Usualmente el programa del PAC sigue siendo único. La carga/descarga del código sobre el PAC, el acceso a la entrada/salidas e incluso el enlace del sistema de supervisión con el PAC no se han de modificar, siendo transparente para el usuario la sincronización con el PAC secundario. El trabajo más crítico de un sistema redundante consiste en mantener sincronizados el primario con el secundario.
Hay que ser conscientes de que durante los cálculos del programa se modifican los valores de la memoria, temporizadores, contadores, marcas… también hay que considerar que el sistema de supervisión modifica parámetros del sistema en la memoria del PAC primario, e incluso el usuario puede que este modificando el código o forzando salidas desde la consola de programación. Todos estos cambios en la memoria del PAC primario deben ser enviados al PAC secundario de forma transparente, para que llegado el momento de conmutar (que no sabemos cuándo será) se produzca una transición que no provoque discontinuidad de los accionamientos.
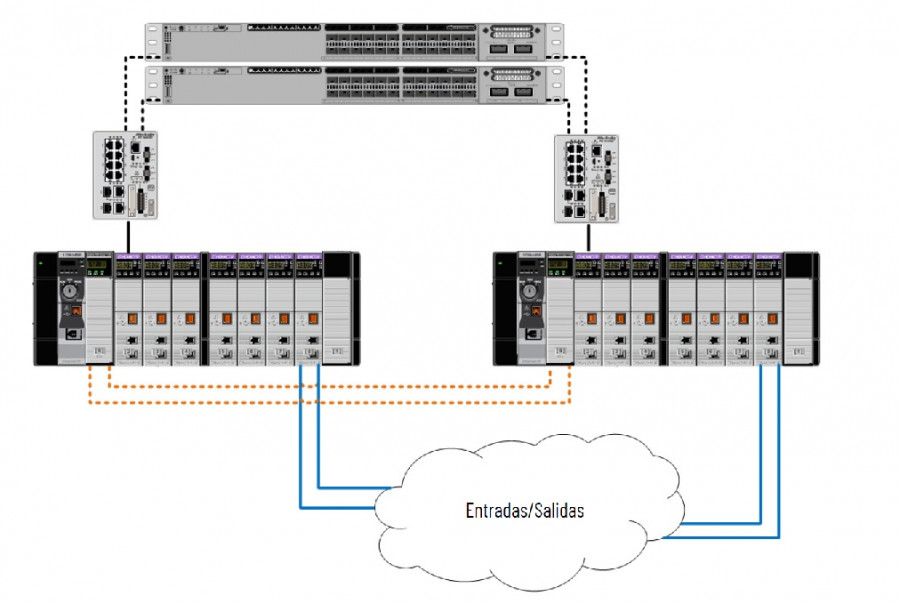
En la imagen podemos ver una representación de un sistema formado por un PAC en redundancia que se sincroniza mediante las fibras ópticas de color calabaza, y mantiene el control de una red de entradas salidas representadas por las líneas de comunicación azules.
Una fácil mejora en disponibilidad de un sistema puede ser el uso de fuentes de alimentación redundantes en cada chasis. Ciertamente que al haber dos chasis ya podemos usar dos fuentes independientes, pero ¿Por qué no redundar el componente más susceptible a problemas eléctricos provenientes del exterior?
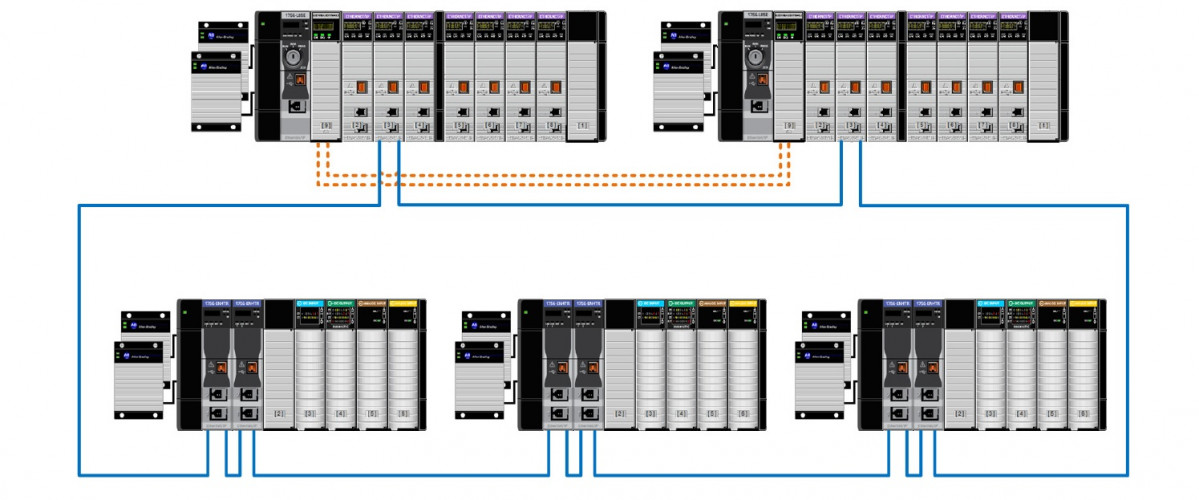
FIGURA 3: PACs redundantes con fuentes de alimentación también redundantes
En el gráfico mostrado vemos que las tarjetas de comunicación Ethernet tienen doble conector para permitir montar una red de entradas salidas en anillo y sin switches, pero dejando por el momento el tema de la disponibilidad de la red, lo que hay que considerar llegados a este punto es sobre la disponibilidad de las entradas salidas.
Un primer nivel de redundancia en los equipos distribuidos de entradas/salidas se obtiene al duplicar las cabeceras de comunicación.
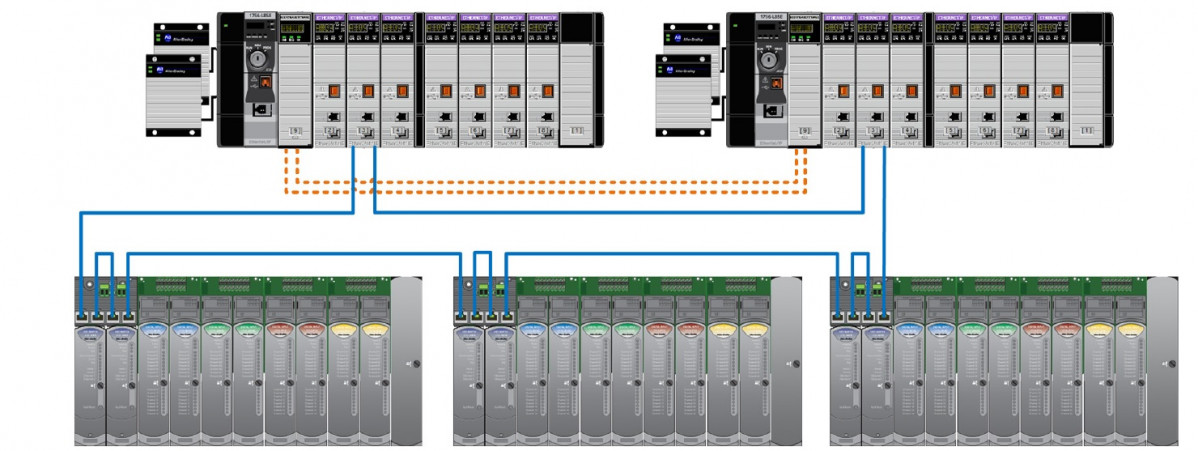
FIGURA 4: PACs redundantes con módulo de E/S 1756 con doble cabecera, todo con fuentes redundantes en un anillo de comunicaciones con protocolo DLR.
Pero si realmente necesitamos montar un sistema de seis “9s” también tendremos que redundar totalmente las E/S.
Históricamente en la industria se han usado sistemas montados a mano, con diodos o aisladores externos para permitir unir entradas en paralelo, y luego mediante lógica en el PAC determinar si falla una tarjeta/señal. En el caso de las salidas mediante el uso de relés, diodos y aisladores también se puede conseguir este efecto de duplicidad de tarjetas. Pero aparte de difíciles de mantener, el diagnostico de los componentes involucrados no es nada simple.
Por ello hay en el mercado entradas/salidas remotas donde el diagnóstico está integrado en las propias tarjetas que por supuesto se pueden sustituir en caliente y donde no hay necesidad de “inventos” externos. La información de las tarjetas ya llega de forma unificada al PAC de forma que los valores no necesitan ser trabajados, solo hay que mantener la vigilancia, mediante la configuración de alarmas, sobre la salud de las tarjetas.
Diseño de red
El diseño de la red está muy ligado al protocolo de comunicación que usa el PAC, ya que la redundancia o alta disponibilidad de las comunicaciones se rige por normas/protocolos que residen en los switches que conforman la red.
Los protocolos de comunicación que usa Ethernet y se basan en la capa de transporte TCP y UDP, se apoyan en las capas de “Red”, “Enlace” y/o “Física”. Por tanto, pueden usar cualquier protocolo de baja resiliencia, actual o futuro, que esté basado en la capa de “Red-Enlace”.
Existen varios protocolos actuales en la capa “Red-Enlace” que aportan esta baja resiliencia a las redes Ethernet estándar.
Los protocolos más atractivos son los que tienen un tiempo de convergencia más bajo. A nivel IT, los protocolos STP, REP y la arquitectura de estrella redundante son muy usados, por lo que es normal encontrarse este tipo de protocolos en la capa de supervisión donde tiempos de resiliencia de entre 50 y 250 milisegundos son aceptables.
En lo que respecta a la red de entradas-salidas suele recomendarse usar protocolos con tiempos de convergencia más rápidos como por ejemplo el DLR (Device Level Ring). El protocolo de anillo DLR tiene un tiempo de recuperación de 3 ms para un anillo con 50 participantes y se puede hacer sin más dificultad que activando el supervisor en uno de los participantes.
Este protocolo es típico en los anillos de las E/S por su facilidad de configuración e inmejorable diagnóstico.
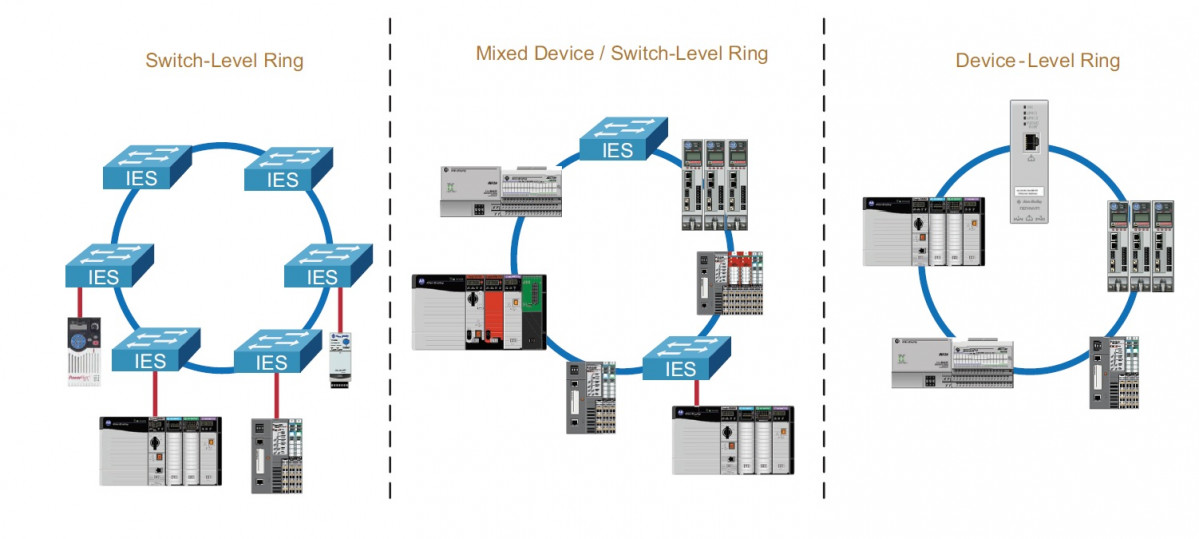
FIGURA 5: Ejemplo de red con protocolo DLR y formada por switches. Centro: Ejemplo de red con protocolo DLR mezclando switches y equipos finales. Derecha: Ejemplo de red con protocolo DLR integrado en los equipos finales.
En el caso límite de necesitar una red que no deba caer en caso de rotura de uno de sus componentes ni tan siquiera por pocos milisegundos, podemos usar el protocolo PRP Parallel Redundancy Protocol, norma IEC 62439-3. Este protocolo se basa en el envío de forma simultánea de todos los paquetes por dos redes independientes (red A y red B) para llegar a su destino, si una de las dos redes tiene un problema y deja de trabajar unos pocos milisegundos o incluso sufre un colapso total, los paquetes de comunicación han seguido llegando al destinatario por la otra red sin perderse ninguno.
Actualizaciones en línea
Es una característica imprescindible cuando en una instalación hay que realizar mejoras o aumentar su tamaño. Es más, permite testear las modificaciones de código antes de su implantación definitiva con la posibilidad de “vuelta a tras” en un solo click. Las modificaciones realizadas sobre el PAC primario una vez testeadas y aceptadas por el programador, son sincronizadas de forma transparente sobre el PAC secundario.
Otra actualización muy importante que puede requerir un PAC es la adición de nuevo hardware a ser controlado. Igual que con el código, los PAC permiten la adición de nuevos equipos estando en marcha. La adición de una nueva tarjeta de E/S, un nuevo variador, etc., es tan simple como dibujar en el árbol de E/S esté nuevo dispositivo. Cuando el hardware este operativo, el PAC creará el enlace de datos para su gestión. Por descontado que el PAC secundario recibirá esta información del PAC primario de forma transparente para permanecer sincronizado en lo que se refiere a equipos remotos a controlar.
El último tipo de actualizaciones en línea que puede requerir una instalación es el referente a la modificación del firmware de alguno de los componentes del conjunto redundante. Es usual que con el tiempo aparezcan nuevas prestaciones en el firmware de los componentes, y el sistema ha de estar pensado para permitir su actualización sin parar la instalación. Usualmente el procedimiento consiste en la desincronización del PAC primario del secundario, esto permite trabajar en la actualización del secundario sin interferir en el proceso, luego forzar una conmutación del primario al secundario (permaneciendo desincronizados), repetir la intervención en el segundo equipo y finalmente activando la sincronización de los dos equipos. Es un proceso delicado ya que durante el tiempo que dura la actualización no está operativa la redundancia y aunque no hay que parar la instalación, estamos corriendo un riesgo extra.
Virtualización
La virtualización se refiere al soporte del software del sistema de supervisión. En este punto, el PAC es un objeto pasivo y la mejora en disponibilidad no está relacionado con el PAC. Son los diferentes softwares, servidores de datos, clientes, servidores de pantalla, bases de datos, etc., los que mediante el uso de plataformas de virtualización mantienen el sistema de supervisión operativo ante el fallo de uno de sus componentes.
Diagnósticos
Este punto, tiene una importancia muy relevante en la manejabilidad de la instalación y es dependiente de la inversión en horas de programación que se haya realizado por parte del integrador.
Por ejemplo: Salidas que han perdido su carga o que tienen un cortocircuito y se han autoapagado para proteger la electrónica de salida. Entradas que tienen detección de hilo roto. Analógicas fuera de rango 4-20 miliamperios. Tarjetas estropeadas que no comunican. Chasis de E/S rotos o sin alimentación. Conexiones de red Ethernet que están funcionando en half-duplex por problemas en el medio físico. Anillos Ethernet abiertos. Trafico Ethernet con volúmenes fuera de lo normal. Estado de la redundancia y de los módulos de los PAC e incluso la posición de la llave mecánica que tienen los PAC en su frontal. Todos estos son ejemplos de diagnósticos que el sistema redundante tiene y que se deben mostrar de forma coordinada.
La diferencia entre montar un buen diagnóstico coordinado, donde el operador sepa en todo momento donde reside la raíz del problema y por tanto pueda reaccionar rápidamente en su resolución, o montar un diagnóstico sin coordinación es el tiempo medio necesario para su localización y resolución. El MTTR (Mid Time To Repair) de un sistema redundante bien diagnosticado puede ser de unos 15 minutos (básicamente el tiempo de ir a cambiar una pieza concreta en un armario concreto en caliente) a ser de horas si el diagnóstico es escaso o está mal estructurado. Afortunadamente, el hecho de ser redundante nos permite cierta tranquilidad durante el tiempo de reparación ya que el sistema no ha caído.
Conclusiones
Como conclusión podemos afirmar que con los PACs es técnicamente muy sencillo implementar un sistema de control redundante a cualquier nivel, fuentes de alimentación, controladores, red Ethernet, supervisión y entradas salidas. La casi nula adición de horas de ingeniería en el diseño y puesta en marcha de la redundancia hace que la decisión de implementar las técnicas explicadas, o de no implementarlas, pase a ser un equilibrio puro entre disponibilidad necesaria y coste de los materiales.Invertir en un sistema redundante de alta disponibilidad en contraposición a uno de disponibilidad simple puede tener una gran diferencia en pérdida de tiempo o costes debidos a paradas no planificadas.
Daniel Benitez
Technology Consultant en Rockwell Automation
Este artículo aparece publicado en el nº 528 de Automática e Instrumentación
Págs. 45 a 47.

")

El 88% de las compañías tiene dificultades para captar talento en nuevos perfiles




Tokiota congrega a profesionales y altos cargos de compañías del sector industrial durante un encuentro organizado junto al Observatorio de Industria y Tecnología



Comau y Omron Robotics ofrecen soluciones de automatización flexibles y escalables para la industria
A nivel global y en sectores de alto crecimiento
Empresas destacadas

Comentarios